
上一篇(http://my.oschina.net/penngo/blog/517223),本文使用HBase的java客户端api操作Hbase。
需要用到的包可以在/opt/cloudera/parcels/CDH-5.4.7-1.cdh5.4.7.p0.3/jars找到,hbase版本1.0.0
HbaseTest3.java代码例子
import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.MasterNotRunningException;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.ZooKeeperConnectionException;import org.apache.hadoop.hbase.client.Connection;import org.apache.hadoop.hbase.client.ConnectionFactory;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.client.Table;import org.apache.hadoop.hbase.filter.BinaryPrefixComparator;import org.apache.hadoop.hbase.filter.Filter;import org.apache.hadoop.hbase.filter.RowFilter;import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;import org.apache.hadoop.hbase.filter.SubstringComparator;import org.apache.hadoop.hbase.filter.ValueFilter;import org.apache.hadoop.hbase.util.Bytes;public class HbaseTest3 { private Connection connection = null; public HbaseTest3() { } public void createTable(String tableName) { try { System.out.println("start create table ......"); Connection con = this.getConnection(); HBaseAdmin hBaseAdmin = (HBaseAdmin) con.getAdmin(); if (hBaseAdmin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建 hBaseAdmin.disableTable(tableName); hBaseAdmin.deleteTable(tableName); System.out.println(tableName + " is exist,detele...."); } HTableDescriptor tableDescriptor = new HTableDescriptor( TableName.valueOf(tableName)); tableDescriptor.addFamily(new HColumnDescriptor("column1")); tableDescriptor.addFamily(new HColumnDescriptor("column2")); tableDescriptor.addFamily(new HColumnDescriptor("column3")); hBaseAdmin.createTable(tableDescriptor); System.out.println("create table success......"); } catch (MasterNotRunningException e) { e.printStackTrace(); } catch (ZooKeeperConnectionException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public void insertData(String tableName) { System.out.println("start insert data ......"); try { Connection con = this.getConnection(); Table table = con.getTable(TableName.valueOf(tableName)); // HTablePool pool = new HTablePool(configuration, 1000); // HTable table = (HTable) pool.getTable(tableName); Put put = new Put("112233bbbcccc".getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值 put.addColumn("column1".getBytes(), null, "aaa2".getBytes());// 本行数据的第一列 put.addColumn("column2".getBytes(), null, "bbb2".getBytes());// 本行数据的第三列 put.addColumn("column3".getBytes(), null, "ccc2".getBytes());// 本行数据的第三列 table.put(put); // pool.getTable(tableName).put(put); } catch (IOException e) { e.printStackTrace(); } System.out.println("end insert data ......"); } public void queryAll(String tableName) { // HTablePool pool = new HTablePool(configuration, 1000); // HTable table = (HTable) pool.getTable(tableName); try { Connection con = this.getConnection(); Table table = con.getTable(TableName.valueOf(tableName)); ResultScanner rs = table.getScanner(new Scan()); for (Result r : rs) { System.out.println("获得到rowkey:" + new String(r.getRow())); for (KeyValue keyValue : r.raw()) { System.out.println("列:" + new String(keyValue.getFamily()) + "====值:" + new String(keyValue.getValue())); } } } catch (IOException e) { e.printStackTrace(); } } public void queryByCondition1(String tableName) { try { Connection con = this.getConnection(); Table table = con.getTable(TableName.valueOf(tableName)); Get scan = new Get("112233bbbcccc".getBytes());// 根据rowkey查询 Result r = table.get(scan); System.out.println("获得到rowkey:" + new String(r.getRow())); for (KeyValue keyValue : r.raw()) { System.out.println("列:" + new String(keyValue.getFamily()) + "====值:" + new String(keyValue.getValue())); } } catch (IOException e) { e.printStackTrace(); } } public void queryByCondition2(String tableName) { try { Connection con = this.getConnection(); Table table = con.getTable(TableName.valueOf(tableName)); Filter filter = new SingleColumnValueFilter( Bytes.toBytes("column1"), null, CompareOp.EQUAL, Bytes.toBytes("aaa2")); // 当列column1的值为aaa时进行查询 Scan s = new Scan(); s.setFilter(filter); ResultScanner rs = table.getScanner(s); for (Result r : rs) { System.out.println("获得到rowkey:" + new String(r.getRow())); for (KeyValue keyValue : r.raw()) { System.out.println("列:" + new String(keyValue.getFamily()) + "====值:" + new String(keyValue.getValue())); } } } catch (Exception e) { e.printStackTrace(); } } public void queryByCondition3(String tableName) { try { Connection con = this.getConnection(); Table table = con.getTable(TableName.valueOf(tableName));// 提取rowkey以cccc结尾数据// Filter filter1 = new RowFilter(CompareOp.EQUAL,new RegexStringComparator(".*cccc$"));//// 提取rowkey以包含bbb的数据// Filter filter1 = new RowFilter(CompareOp.EQUAL,new SubstringComparator("bbb"));// 提取rowkey以123开头的数据 Filter filter1 = new RowFilter(CompareOp.EQUAL,new BinaryPrefixComparator("1122".getBytes()));// Filter filter1 = new RowFilter(CompareOp.EQUAL,// new BinaryComparator(Bytes.toBytes(rowkey))); Scan scan = new Scan(); scan.setFilter(filter1); ResultScanner rs = table.getScanner(scan); for (Result r : rs) { System.out.println("获得到rowkey:" + new String(r.getRow())); for (Cell cell : r.rawCells()) { System.out.println("列:" + new String(CellUtil.cloneFamily(cell)) + "====值:" + new String(CellUtil.cloneValue(cell))); } } rs.close(); } catch (Exception e) { e.printStackTrace(); } } public void queryByCondition4(String tableName) { try { Connection con = this.getConnection(); Table table = con.getTable(TableName.valueOf(tableName)); Filter filter1 = new ValueFilter(CompareOp.EQUAL, new SubstringComparator("aaa2")); Scan scan = new Scan(); scan.setFilter(filter1); ResultScanner rs = table.getScanner(scan); for (Result r : rs) { System.out.println("获得到rowkey:" + new String(r.getRow())); for (Cell cell : r.rawCells()) { System.out.println("列:" + new String(CellUtil.cloneFamily(cell)) + "====值:" + new String(CellUtil.cloneValue(cell))); } } rs.close(); } catch (Exception e) { e.printStackTrace(); } } public void close() throws IOException { if (connection != null) { connection.close(); } } public Connection getConnection() throws IOException { Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.property.clientPort", "2181"); configuration.set("hbase.zookeeper.quorum", "192.168.17.108"); if (connection == null) { connection = ConnectionFactory.createConnection(configuration); } return connection; } public static void main(String[] args) { HbaseTest3 hbaseTest = new HbaseTest3(); try { String tableName = "test1"; hbaseTest.createTable("test1"); hbaseTest.insertData("test1"); hbaseTest.queryAll("test1"); // hbaseTest.queryByCondition1(tableName);// hbaseTest.queryByCondition2(tableName);// hbaseTest.queryByCondition3(tableName);// hbaseTest.queryByCondition4(tableName); hbaseTest.close(); } catch (Exception e) { e.printStackTrace(); } }}
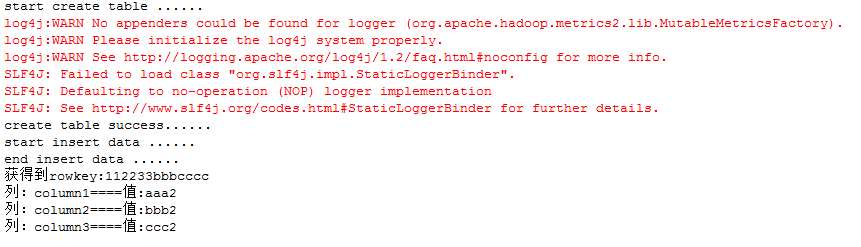
运行结果:
HBase过滤器提供了非常强大的特性来帮助用户提高其处理表中数据的效率。用户不仅可以使用HBase中已经定义好的过滤器,还可以自定义过滤器。
Get和Scan两个类都支持过滤器。
CompareFilter中的比较运算符
| 操作 | 描述 |
|---|---|
| LESS | 匹配小于设定值的值 |
| LESS_OR_EQUAL | 匹配小于或等于设定值的值 |
| EQUAL | 匹配等于设定值的值 |
| NOT_EQUAL | 匹配大于设定值不相同的值 |
| GREATER_OR_EQUAL | 匹配大于或等于设定值的值 |
| GREATER | 匹配大于设定值的值 |
| NOT_OP | 排除一切值 |
比较器
| 比较器 | 描述 |
|---|---|
| BinaryComparator | 使用Bytes.compareTo()比较当前值与阈值 |
| BinaryPrefixComparator | 与上面的相似,使用Bytes.compareTo()进行匹配,但是是从左端开始前缀匹配 |
| NullComparator | 不做匹配,只判断当前值是不是null |
| BitComparator | 通过BitwiseOp类提供的按位与(AND),或(OR),异或(XOR)操作执行位级比较 |
| RegexStringComparator | 根据一个正则表达式,在实例化这个比较器的时候去匹配表中数据 |
| SubstringComparator | 把阈值和表中数据当做String实例,同时通过contains()操作匹配字符串 |
比较过滤器
RowFilter(行过滤器)
行过滤器是基于行键来过滤数据
FamilyFilter(列族过滤器)
列族过滤器是基于列族来进行过滤数据
QualifierFilter(列名过滤器)
列名过滤器用户筛选特定的列
ValueFilter(值过滤器)
值过滤器用户筛选某个特定值的单元格。与RegexStringComparator配合使用,可以使用功能强大的表达式来进行筛选。
DependentColumnFilter(参考列过滤器)
参考列过滤器不仅仅简单的通过用户指定的信息筛选数据,还允许用户指定一个参考列或是引用列。并使用参考列控制其他列的过滤。
专用过滤器
SingleColumnValueFilter
用一列的值决定是否一行数据是否被过滤
SingleColumnValueExcludeFilter(单列排除过滤器)
该过滤器继承SingleColumnValueFilter,反考烈不会包含在结果中。
PrefixFilter(前缀过滤器)
筛选出具有特点前缀的行键的数据。扫描操作以字典序查找,当遇到比前缀大的行时,扫描结束。PrefixFilter对get()方法作用不大。前缀过滤器只针对行键。
PageFilter(分页过滤器)
可以使用这个过滤器对结果按行分页。当用户创建PageFilter的实例的时候,指定了pageSize,这个参数可以控制每页返回的行数。
KeyOnlyFilter(行键过滤器)
只返回每行的行键,不返回值。对于之关注于行键的应用常见来说非常合适,不返回值,可以减少传递到客户端的数据量,能起到一定的优化作用。
FirstKeyOnlyFilter(首次行键过滤器)
只想返回的结果集中只包含第一列的数据
InclusiveStopFilter(包含结束的过滤器)
开始行被包含在结果中,单终止行被排除在外,使用这个过滤器,也可以将结束行包含在结果中。
TimestampFilter(时间戳过滤器)
使用时间戳过滤器可以对扫描结果中对版本进行细粒度的控制。
ColumnCountGetFilter(列计数过滤器)
确定每行最多返回多少列,并在遇到一定的列数超过我们锁设置的限制值的时候,结束扫描操作
ColumnPaginationFilter(列分页过滤器)
与PageFilter类似,列分页过滤器可以对一行的所有列进行分页。
ColumnPrefixFilter(列前缀过滤器)
类似PrefixFilter,列前缀过滤器通过对列名进行前缀匹配过滤
RandomRowFilter(随机行过滤器)
随机行过滤器可以让结果中包含随机行。
附加过滤器
SkipFilter(跳转过滤器)
与ValueFilter结合使用,如果发现一行中的某一列不符合条件,那么整行都会被过滤掉。
WhileMatchFilter(全匹配过滤器)
如果你想想要在遇到某种条件数据之前的数据时,就可以使用这个过滤器,当遇到不符合设定条件的数据的时候,整个扫描也结束了。
自定义过滤器
可以通过实现Filter接口或者直接竭诚FilterBase类来实现自定义过滤器。